
Collaboratively, we can put
an end to Cruel and unproductive speech online
Collaboratively, we can put
an end to Cruel and unproductive speech online
Toxicity on the internet is a major problem for platforms
and publications. Abuse and bullying on the internet suppress vital voices, while inappropriate comments, even if they're not directed to us, can deter users from seeking important information and sour everyone's online experience.
It should come as no surprise that cyberbullying has become such an issue. To see how big of a problem this is, here are all the stats about cyberbullying from 2021 that you need to know:
Step

01
Step

03
Step

05
Step

07
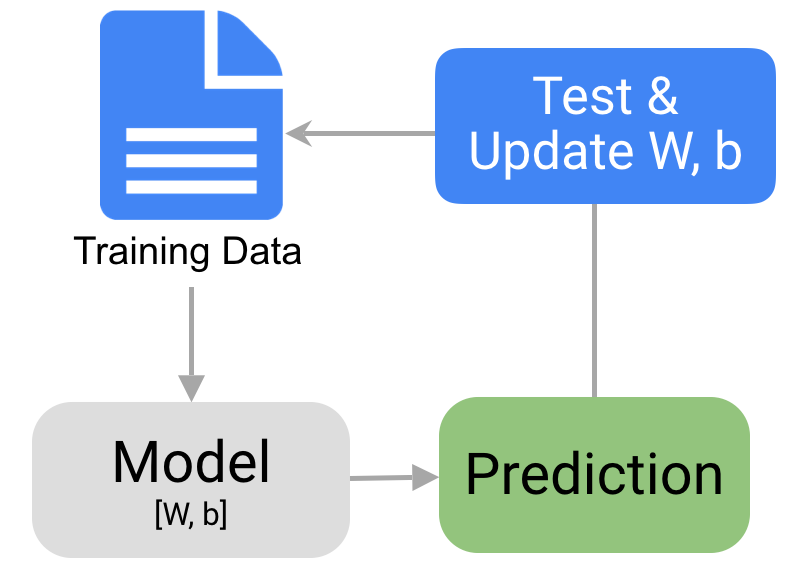
Collect Data! There are several Kaggle datasets to choose from. Ultimately, we went with a Kaggle Jigsaw Dataset.
Data preparation! Prep our data to use in our model training by loading it into an appropriate location.
Evaluation! Using data that has never been used for training, we will put our model to the test.
Share to our audience!
Research! Learn about BERT (Bidirectional Encoder Representations from Transformers) and Transformer.
Train our model using the Jigsaw Dataset – utilize our data to enhance our model's ability to predict whether or not a particular text is toxic.
Create a webpage to showcase our efforts!
Step
02
Step
04
Step

06
During our work process/planning to create the toxic comment identifier, we considered three main resources:
First, the dataset we used was referenced from Kaggle and was a dataset containing 6 different categories of hate speech. These labels were created by humans and not by the computer.
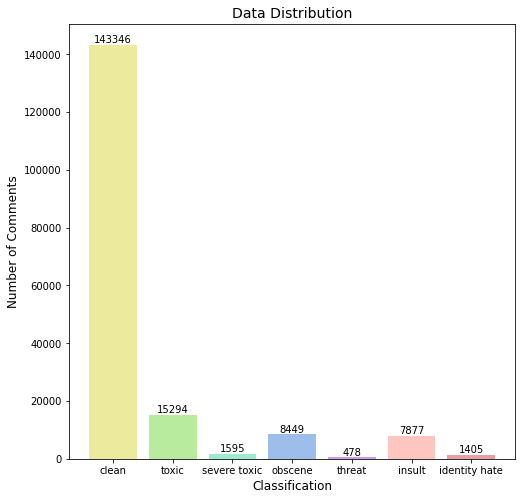
As shown above, the graph shows the amount of comments per category. Most of the comments were clean (positive) and the least were comments in the threat category. In the middle would be the comments that would be distinguished as toxic, showing that media hate is still a perverse topic. Keep in mind that this visualization shows how each comment would be classified as, NOT the type.
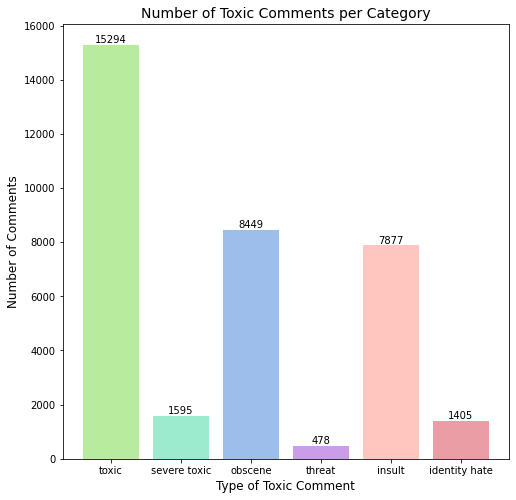
This graph compares the prevalence of different forms of hate speech. Same with the previous graph, this graph has more clean comments, yet there is still a significant amount of both obscene and insulting comments. Remarks categorized as threats or identity hate are significantly more common in our dataset than threats and identity hate comments. This is not a classification, rather this visual shows what level of toxicity each comment is remarked as.
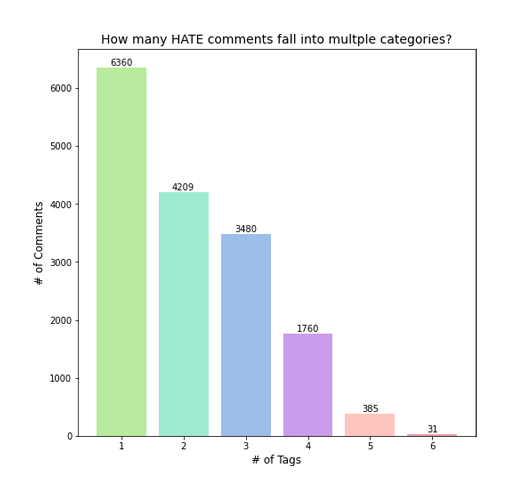
Many of the comments in the dataset fit into multiple categories. For example, a certain comment might be both obscene and an insult. This bar graph depicts how often comments have 1, 2, 3, 4, 5, or all 6 categories.
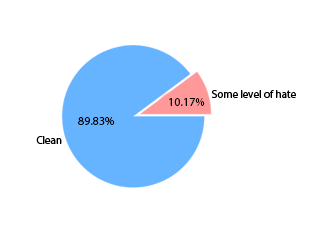
This graph demonstrates that the majority of the comments in our dataset were clean, with just a small fraction containing some toxicity.
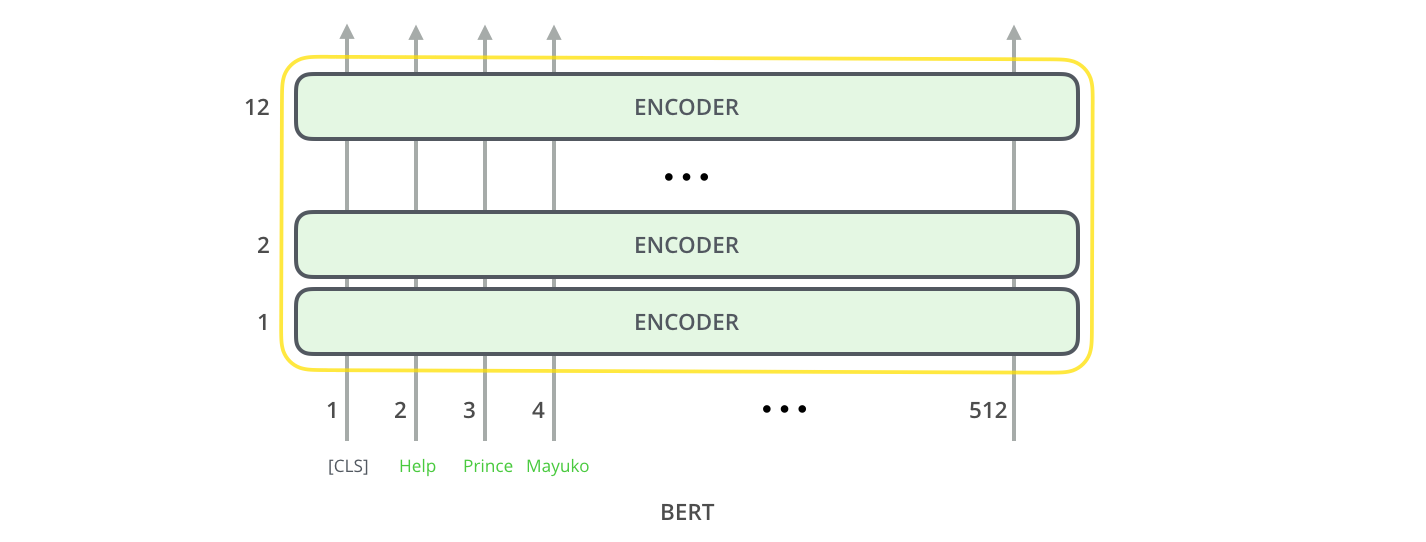
BERT is a Transformer model that solely utilizes encoders. These encoders can be combined with outside word embeddings or be used to extract word embeddings based on the data, as we chose to do.
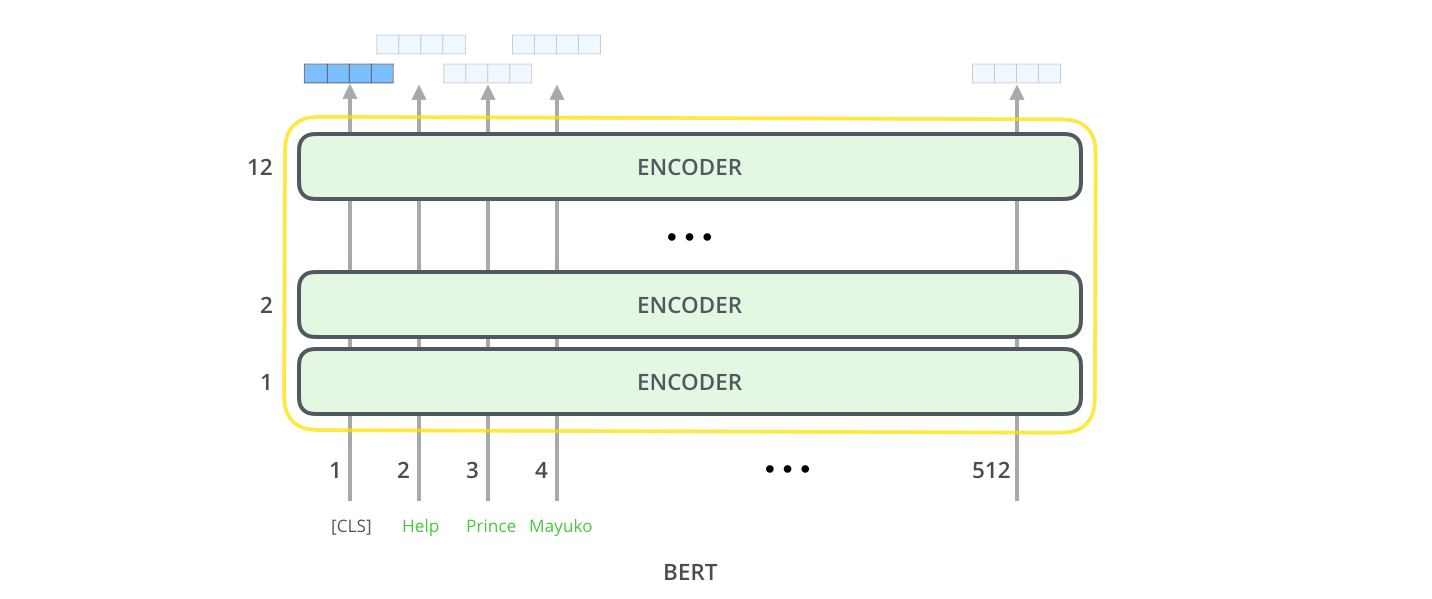
The inputted text is passed through these encoders, which, as described above under Transformer, make sense of the sentence using word relationships and, in our case, extract word meanings.
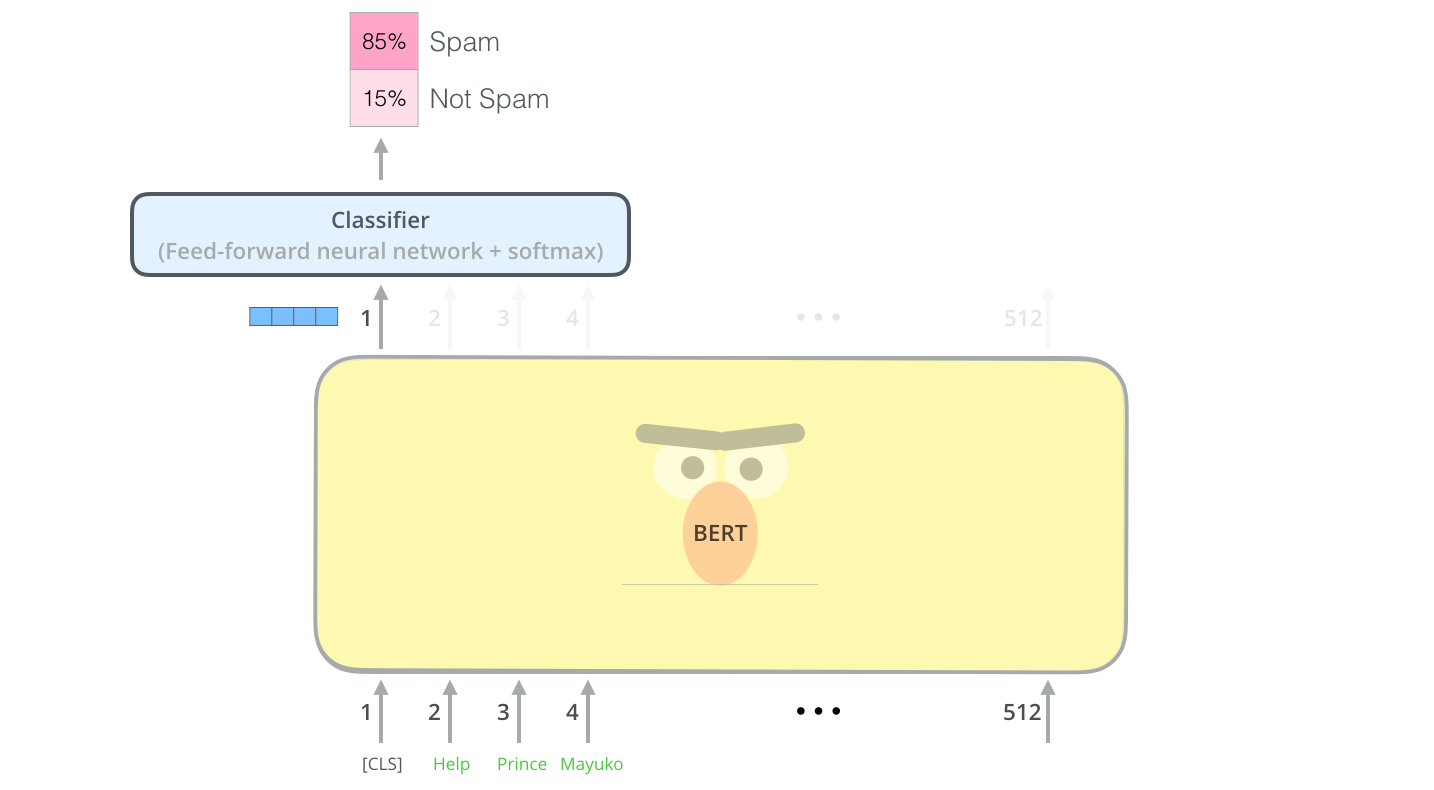
BERT's output captures individual word meanings and overall sentence understanding in a computer-readable way. This can be passed on to a classifier, which, in our case, labels the input based on its level of toxicity.
We used a simple linear classifier followed by the sigmoid function in order to get our final output: whether the inputted comment is toxic, severely toxic, obscene, a threat, an insult, identity hate, some combination thereof, or none of the above.
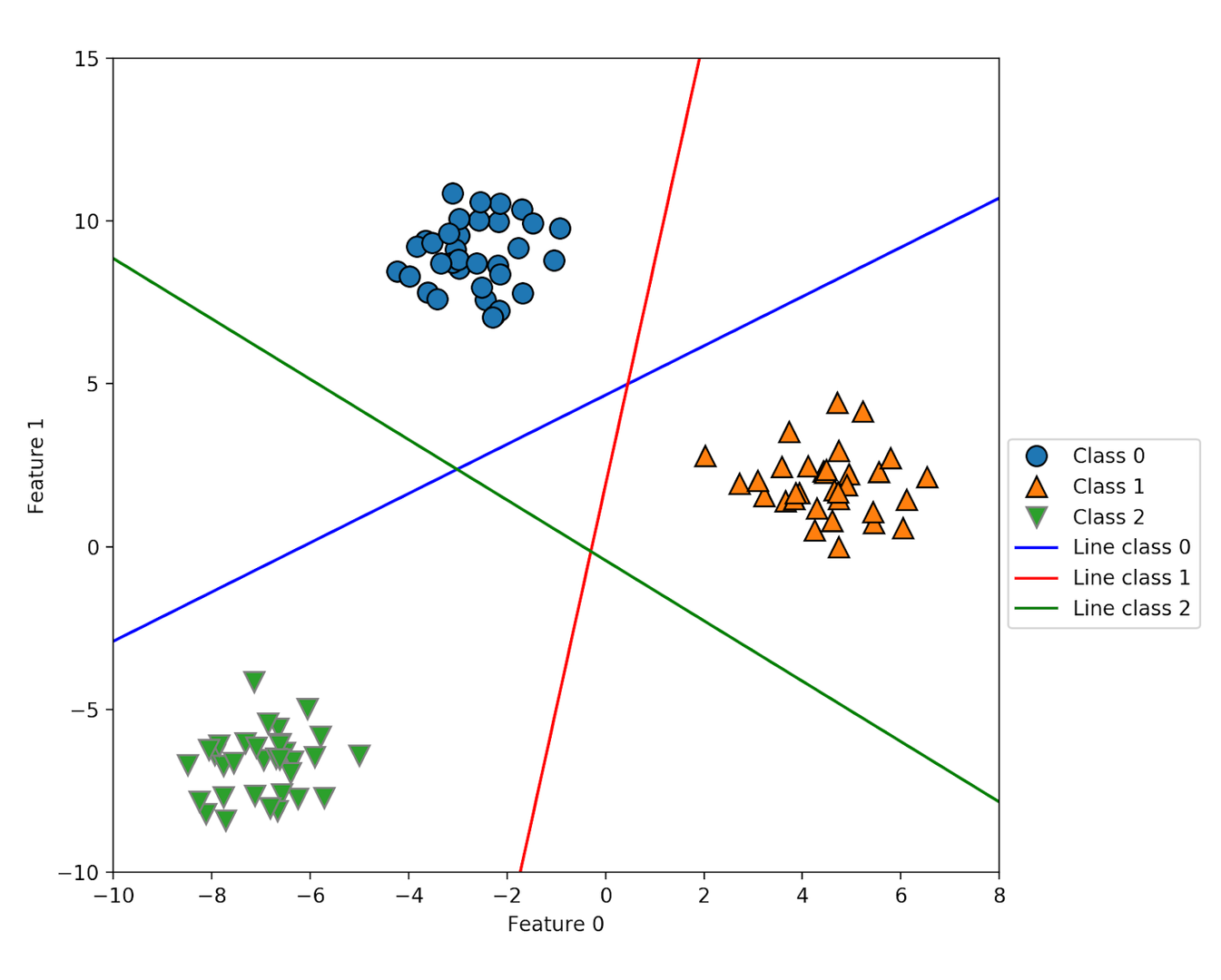
An example of a multi-class linear classifier
The linear classifier uses past data to predict which category future data will fall into. The input (a collection of features extracted by BERT) is weighted based on which of those features are most important to figuring out the class, and then passed on to the sigmoid function, which provides a probability for each category, indicating how likely the input is toxic, a threat, etc.
We were drawn to the idea of toxic comment identification because of its uniquely modern applications. Today's lifestyles have become considerably more digitally focused, with online interactions being nearly as common as in-person encounters. The coronavirus pandemic has only exacerbated this trend, causing daily tasks to be done more than ever before over the Internet. Although we all know that the online world can be a wonderful place for connecting and learning, we also know that it can be an outlet for obscenity, hate speech, and general toxicity. We hope our program can be used to mitigate this phenomenon and help steer online conversations towards creating a more positive and productive environment.

Bella is a rising sophomore at Alameda High School. In her free time, she enjoys reading, cooking, and playing the flute. Prior to this camp she only had limited programming knowledge but greatly enjoyed participating on her middle school’s robotics team. In the future, she hopes to continue expanding her AI and programming knowledge, as well as exploring how both could intersect with all of her other interests to have a positive impact on the world.

Elisa is a rising junior at Mission San Jose High School. She enjoys doing all different forms of art as she herself attends a weekly art academy. Along with art, she loves to bake for family & friends, listen to music, watch horror movies, and play tennis for recreational purposes. Her main purpose for joining AI Camp was to gain a some exposure to different branches of programming, since our future depends on it, but in actuality, she aspires to major in Psychology in hopes of going into a medical field related career.

Kimberly is a rising Freshman at Westridge School. She is a co-founder of a non-profit organization called Madhatter Knits, in which during her free time she loves knitting beanies for premature babies in the NICU. In addition, Kimberly loves tennis, playing her zither, and making ceramic pieces! Her goal is to continue to acquire more knowledge on AI to make a global impact!

Rachel is a rising sophomore. Outside of academics, she often swims, enjoys gaming and reading novels. Rachel joined AI Camp to gain exposure to and learn more about AI with a few years of prior coding experience. Looking forward, she also hopes to study CS or other computer-related engineering in the future.

Shreeya is a rising junior at American High School. In her free time, she enjoys reading, watching TV, and playing board games with her friends and family. She is dedicated to helping everyone receive a high quality education and is the founder of an organization called Empowering Kidzz, where kids can attend free classes led by high schoolers. She is also a part of other clubs and organizations like GenUp, FAYE, Interact, and L- Connection and aims to make the world a better place. Shreeya joined AI Camp with the hopes to gain more exposure in this field and she hopes to one day be able to use these skills to help her community.

Justin is an undergraduate at UCLA and served as the group's product manager and instructor. Justin is passionate about education and holds a dedicated interest in fair machine learning.